(This is the updated version of this report from 2019. Download the full slide here. 下載完整簡報)
Mozilla Community Space Taipei “摩茲工寮” is an event / meeting / co-working space and shelter for the local Mozillians, open-source contributors, and civil-society hackers.
It is the first of this kind of Mozilla volunteer-led space. (and another one is Jakarta Space). These spaces are funded by the Mozilla Participation Team, and managed by local Mozillian volunteers.
Here, I will share some brief status of the Taipei Space.
(I’ll use “MozTW Space” or “Space” as the abbreviation for “Mozilla Community Space Taipei” below.)
摩茲工寮是 Mozilla 與開放原始碼、開放資料、開放文化,以及公民駭客的基地。台北的摩茲工寮,是首個 Mozilla 資助成立的志工空間,現行另一個 Mozilla Community Space 在印尼的雅加達。
以下我將會分享摩茲工寮至今的相關數據。
MozTW, Mozilla 台灣社群 (Mozilla Taiwan Community)
Mozilla Taiwan Community (MozTW) is a local Mozilla volunteer community. We have contributed to localizing, promoting Firefox, Mozilla, and open cultures to Mozilla and open source projects since 2004.
MozTW 是在地的 Mozilla 志工社群。我們自 2004 年持續在翻譯及推廣 Mozilla、Firefox 及開放文化上貢獻至今。
The Community Space was initially raised by William Quiviger in 2013, and sponsored by the WPR team. We started the first experimental space in Taipei in the spring of 2014.
After April 2016, the space project transitioned to the Participation Team, supported by Brian King. In February 2017, it was continuous with Open Innovation Group (later Community Team) with the help of George Roter and Konstantina until now.
Community Space 社群空間專案最早由 William Quiviger 於 2013 年發起,台北作為第一個實驗空間,於 2014 年春天成立。
Keyholders
MozTW Space is co-managing by “Keyholders,” 14 local Mozilla volunteers.
Keyholders are all vouched Mozillians and have the same privilege. When they apply for the position, people need to be countersigned by more than a certain percentage of Mozillian visitors (with a community profile and having visited 3 times in the last 3 months). The threshold represents the community’s support to the applicant.
摩茲工寮由 14 位「Keyholder」本地志工共同管理。Keyholder 經 Mozilla community profile 的工寮使用者投票以取得資格。Keyholder 具有同等的權限,可以自由進出與協助其他志工與社群使用工寮空間。
使用者與活動 Visitors & Events
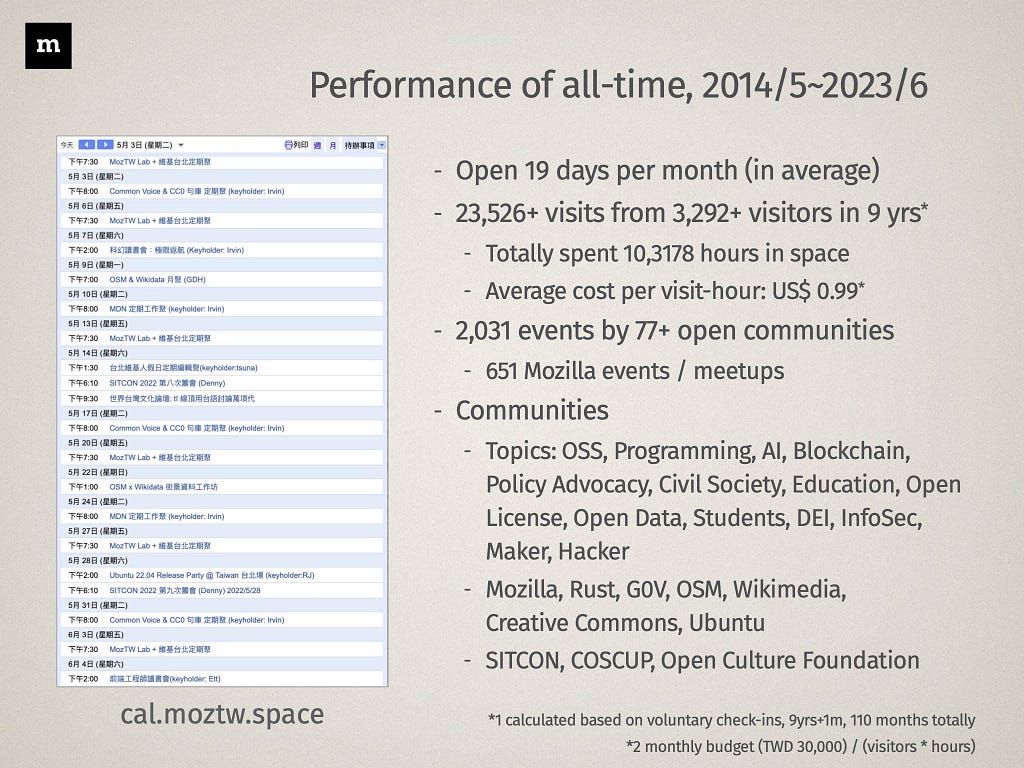
Everyone is welcome to visit the MozTW space when there is any Keyholder inside. However, it’s not opening 24 hours / seven days a week due to the volunteers’ ability. In the last five years, we managed to open the space 19 days per month on average. (Part of the weeknight and most of the time on the weekend)
Besides Mozilla events, we also welcome and support all open culture communities to host their activities in the MozTW Space. More than 23,000 visitors and 2,000 events/meetups from 77 open communities since the soft opening of May 2014.
除了 Mozilla 自己的活動以外,我們也支持所有開放文化社群在此舉辦活動與聚會。自 2014 年五月開幕至今,包含 MozTW 在內,總計有 77 個開放社群,共在此舉辦了超過兩千場活動與聚會,共有超過兩萬三千名參加者與訪客。
The communities that hosted the events at space came from diverse domains, including open source projects, programming, AI, blockchain, policy advocacy, civil society hackers, CS education, open culture, open data, DEI, infoSec, makers & designers.
One of the primary goals is to introduce Mozilla and Open Culture to new friends. In last year (July 2022 — June 2023), more than 260 new visitors had learned about Open Source on their first visit to space (out of 1600 visitors in 183 events).
Not only Mozilla, we also introduce Internet Freedom, Privacy, Digital Policy, Multi-Stackholder Governance, Open Source, Open Data, Open Governance, Public License…all different technologies and ideas around the Internet.
Re-grow the engagement rate to pre-COVID level, which is 55 new visitors out of 260 visitors per month.
Building up the periodic donation structure to fulfill the basic expense of monthly rent and utilities bills.
工寮接下來的短期目標為:
重新增長至疫情前(2019 年)的參與水準:每月 260 名訪客,其中包含 55 名首次到訪者。
建立定期定額的捐款制度,用於租金與水電等基本支出,以維持穩定營運。
捐款支持 Support MozTW Space
We thank Mozilla for sponsoring the Space for the past 9.5 years. Starting from 2024, the budget of the community space will depend on your support.
The volunteer keyholders will keep providing the free space to all open culture events & communities, (including open source, open government, open license, and more.) Please support us at donate.moztw.space ; all the sponsorship will be used for rental and utilities bills.
感謝 Mozilla 過去九年半的資助。自 2024 年起,工寮空間的營運費用,將由 MozTW 社群全額自籌。
摩茲工寮成果報告 - 2014/5~2023/6 was originally published in Mozilla related on Medium, where people are continuing the conversation by highlighting and responding to this story.

 截至 2/21日止 Common Voice 平台上各台灣族語的錄音進度
截至 2/21日止 Common Voice 平台上各台灣族語的錄音進度 賽德克語的錄音介面
賽德克語的錄音介面 Common Voice 台灣專案討論頻道
Common Voice 台灣專案討論頻道
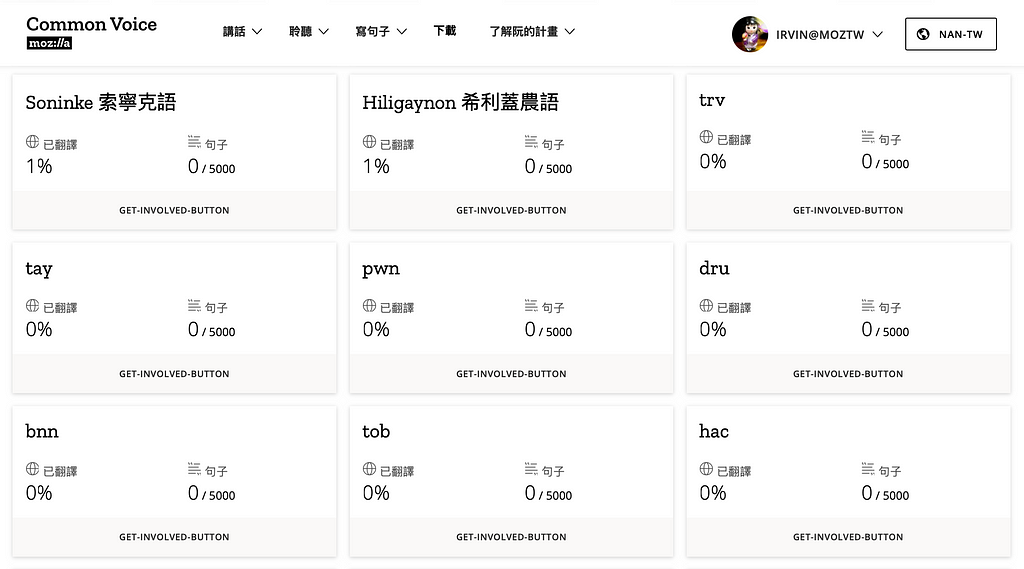 Common Voice 本次新增的在地語言,包含泰雅 tay 排灣 pwn 魯凱 dru 布農 bnn 賽德克 trv 及撒奇萊雅 szy
Common Voice 本次新增的在地語言,包含泰雅 tay 排灣 pwn 魯凱 dru 布農 bnn 賽德克 trv 及撒奇萊雅 szy